Power BI fait le plein de nouveautés assez attendues

Microsoft a dévoilé hier les dernières nouveautés arrivées au cours du mois et attendues pour Power BI Desktop. On retrouve ainsi un certain nombre de nouvelles fonctionnalités de formatage pour les rapports générés ainsi que plusieurs visuels tiers dans AppSource.
En ce qui concerne la création de rapports, deux nouvelles fonctionnalités sont également présentés en beta notamment les étiquettes de sensibilité dans l’exportation PDF , ainsi que la définition de la sécurité au niveau des lignes qui ne nécessite pas d’expressions d’analyse de données complexes (DAX).
Autre point très interessant, mais qui concernera avant tout les utilisateurs avancés et développeurs : Power BI Embedded prend désormais en charge TypeScript, alors que seul JavaScript était pris en charge auparavant. Compte tenue de la popularité croissante de TypeScript (langage dont on oublie même qu’il a été inventé par Microsoft), c’est une bonne nouvelle, cohérente avec l’ensemble de la plateforme de développement de l’éditeur.
La liste complète des améliorations peut être consulté ci-dessous et en suivant ce lien
Reporting
- Mise en forme conditionnelle basée sur des champs de type chaîne de caractères
- cône de résumé visuel Smart Narrative
- Formatage de la largeur des images dans les tableaux et les matrices
- Mise à jour de votre thème de base dans Power BI
- Validation du thème du rapport lors de l’importation du thème personnalisé
- Mise à jour du thème de base dans Power BI
- Nouveaux thèmes de rapport accessibles
- Personnalisation des pages visibles dans le navigateur de page visuel
- Les étiquettes de sensibilité sont désormais prises en charge dans l’exportation PDF à partir du bureau.
- Amélioration de l’éditeur de sécurité au niveau des lignes
- Expérience de création de tableaux formatés pour les rapports paginés (Draft Paginated Reports)
- Créer un rapport paginé à partir d’un datamart
- Planification de la capacité pour les rapports paginés
Analytique
- Quick Create SDK
Modélisation
- Nouvelles fonctions DAX : LINEST et LINESTX
Connecteurs externes
- Denodo (mise à jour du connecteur)
- Digital Construction Works Insights (mise à jour des connecteurs)
- Profisee (mise à jour du connecteur)
Services
- Nouvelle expérience « Get Data » dans le service Power BI
- Vue compacte
- Métriques liées
- Métrique de suivi
Visualisations (visuels tiers)
- Choix de la rédaction du trimestre
- Nouveaux visuels dans AppSource
- Graphique d’analyse des tendances des jalons par Nova Silva
- Multiples Sparklines
- Inforiver Charts 2.1 est maintenant certifié Microsoft Power BI.
- accoPLANNING par Accobat
- Drill Down Donut PRO de ZoomCharts.
L’ancienne page « Get Data » du service Power BI a été entièrement supprimée, les anciens points d’entrée étant remplacés par de nouvelles fonctionnalités dans les espaces de travail.
Toutes ces mises à jour sont accessibles en téléchargeant la dernière version de l’application Desktop.
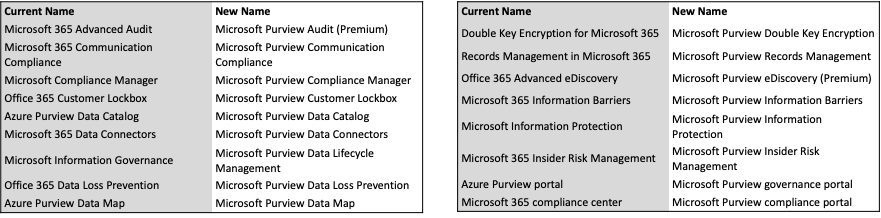





 L’outil Microsoft d’intégration avec les mainframes IBM vient d’être mis à jour. Les plus anciens se souvienne de son lointain ancêtre : OS/2 Communication Server, beaucoup de clients à l’époque comme sans surprise les banques (BNP par exemple) mais aussi la SNCF, la CNAF, etc. Puis vint ensuite sa première version sur Windows NT : SNA Server. Il deviendra HIS (Host Intégration Server) bien plus tard avec une version 2010, 2016 et donc maintenant 2020.
L’outil Microsoft d’intégration avec les mainframes IBM vient d’être mis à jour. Les plus anciens se souvienne de son lointain ancêtre : OS/2 Communication Server, beaucoup de clients à l’époque comme sans surprise les banques (BNP par exemple) mais aussi la SNCF, la CNAF, etc. Puis vint ensuite sa première version sur Windows NT : SNA Server. Il deviendra HIS (Host Intégration Server) bien plus tard avec une version 2010, 2016 et donc maintenant 2020.

