Anthropic rivalise avec OpenAI avec Claude 3

Lundi, Anthropic a publié Claude 3, une famille de trois modèles de langage IA similaires à ceux qui alimentent ChatGPT. Anthropic affirme que ces modèles établissent de nouvelles références industrielles pour toute une série de tâches cognitives, approchant même des capacités « quasi humaines » dans certains cas. Il est disponible dès maintenant sur le site web d’Anthropic, le modèle le plus puissant faisant l’objet d’un abonnement uniquement.
Les trois modèles de Claude 3 représentent une complexité et un nombre de paramètres croissants : Claude 3 Haiku, Claude 3 Sonnet et Claude 3 Opus. Sonnet alimente le chatbot Claude.ai maintenant gratuitement avec une connexion par email. Opus n’est disponible via l’interface de chat web d’Anthropic que si vous payez 20 $ par mois pour « Claude Pro ». Les trois logiciels disposent d’une fenêtre contextuelle de 200 000 tokens.
Difficile de comparer directement les différents modèle dans des conditions objectives, la plupart des tests sont largement controversés, chacun, ô surprise s’estimant meilleur que l’autre dans un segment d’usage particulier. Jusqu’à sa version 2, Anthropic mettait en avant la longueur de la fenêtre contextuelle vs celle de ChatGPT. Avec Claude 3, Anthropic se compare maintenant aussi en terme de performances, un bon signe ?
L’entreprise diffuse des benchs (forcément positifs) sur Claude 3.

Claude 3 aurait démontré des performances avancées dans diverses tâches cognitives, notamment le raisonnement, la connaissance des experts, les mathématiques et la maîtrise du langage. (Malgré l’absence de consensus sur la question de savoir si les grands modèles de langage « savent » ou « raisonnent »…). L’entreprise affirme que le modèle Opus, le plus performant des trois, présente « des niveaux de compréhension et de fluidité proches de ceux de l’homme dans des tâches complexes »… Si Opus est « proche de l’homme » sur certains critères spécifiques, mais cela ne signifie pas qu’Opus possède une intelligence générale comparable à celle d’un être humain (il suffit de penser que les calculatrices de poche sont surhumaines en mathématiques). Il s’agit donc d’une affirmation volontairement accrocheuse qui peut être atténuée par des qualifications.
Selon Anthropic, Claude 3 Opus bat GPT-4 sur 10 tests d’IA, dont MMLU (connaissances de premier cycle), GSM8K (mathématiques d’école primaire), HumanEval (codage) et HellaSwag (connaissances courantes).
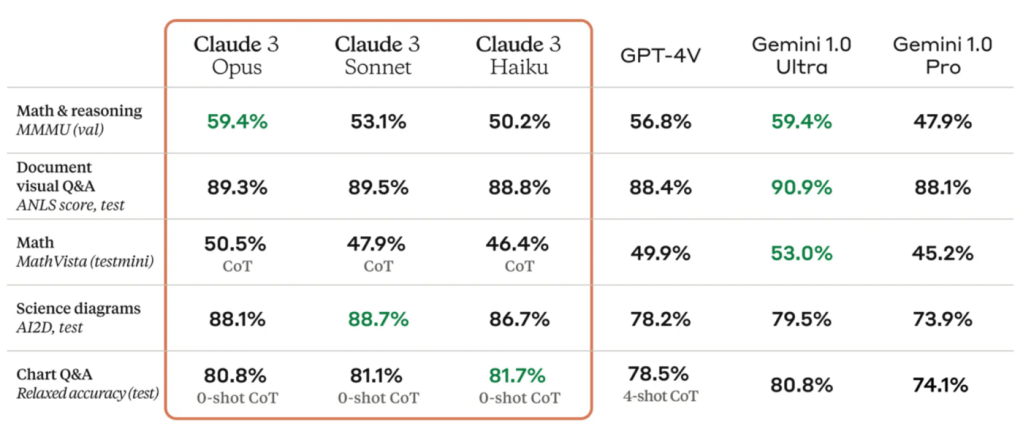
Par rapport à leur prédécesseur, les modèles Claude 3 présentent des améliorations par rapport à Claude 2 dans des domaines tels que l’analyse, les prévisions, la création de contenu, la génération de code et la conversation multilingue. Les modèles seraient également dotés de capacités de vision améliorées, leur permettant de traiter des formats visuels tels que des photos, des graphiques et des diagrammes…
Nous aborderons bien sûr ces différents éléments lors du prochain Briefing Calipia
