Robots qui réfléchissent avant d’agir : l’ambition (très) assumée de Google DeepMind

Google DeepMind vient de dévoiler Gemini Robotics 1.5 et Gemini Robotics-ER 1.5, deux modèles censés inaugurer une nouvelle ère pour la robotique. L’idée est simple à énoncer, beaucoup moins à réaliser : doter les robots d’une capacité de “raisonnement” simulé, leur permettant de planifier avant d’exécuter.
Jusqu’ici, l’approche robotique reposait sur des modèles très spécialisés : un robot entraîné pour souder n’apprendra jamais à plier du linge. Chaque usage demandait des mois de paramétrage, des pipelines logiciels rigides et un investissement conséquent en ingénierie. Pour reprendre les mots de Carolina Parada (responsable de la robotique chez DeepMind) : “installer une cellule robotisée pour une tâche unique peut prendre plusieurs mois”. Autant dire que la promesse d’agilité restait… théorique.
Avec Gemini Robotics, DeepMind propose une rupture : transférer les recettes de l’IA générative (texte, image, vidéo) vers la robotique. Au lieu de coder chaque geste, le robot pourrait recevoir une description de tâche et l’exécuter dans un environnement inconnu.
Deux cerveaux pour une machine
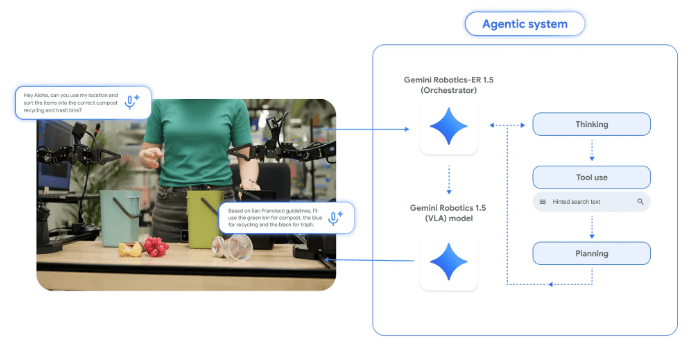
La stratégie repose sur un duo de modèles :
- Gemini Robotics-ER 1.5 : le cerveau “raisonnant”. C’est un modèle vision-langage (VLM) capable de décomposer une tâche complexe en étapes, en s’appuyant sur des données visuelles, textuelles et même des outils externes comme Google Search. L’IA ne manipule rien directement : elle “explique” comment faire.
- Gemini Robotics 1.5 : le bras exécutif. C’est un modèle vision-langage-action (VLA) qui transforme les instructions du premier en mouvements robotiques, tout en ajustant ses gestes grâce au retour visuel. Sa nouveauté : simuler une forme de réflexion intuitive, une sorte de check rapide avant chaque action, afin d’éviter les erreurs grossières (l’équivalent robotique du “vais-je vraiment poser ma tasse sur ce bord instable ?”).
En clair, un modèle écrit le plan, l’autre le réalise.
Universalité ou survente ?
La force revendiquée du système réside dans sa capacité à généraliser. Là où les robots traditionnels exigent des modèles sur-mesure, Gemini 1.5 peut réutiliser des compétences entre machines différentes : apprendre une manipulation sur les pinces d’Aloha 2, puis la transférer sans tuning spécifique aux mains articulées d’Apollo, un humanoïde plus complexe.
Côté usage, les scénarios évoqués restent modestes (tri de linge, assemblages simples). La distance entre démonstration en laboratoire et déploiement industriel demeure abyssale. D’autant que seule la version “ER” est ouverte aux développeurs via Google AI Studio ; la version action (celle qui contrôle réellement les robots) reste confinée aux partenaires de confiance.
Un défi pour les DSI et architectes
Pour les responsables SI, plusieurs questions techniques émergent :
- Comment orchestrer de tels modèles hybrides (raisonnement + action) dans des environnements industriels déjà saturés d’API, de protocoles et de contraintes temps réel ?
- Quel sera le coût de l’adaptation continue des modèles à des environnements hétérogènes ?
- Quels mécanismes de gouvernance mettre en place pour gérer les décisions “intuitives” d’une IA robotique, surtout si elle se trompe ?
En filigrane, DeepMind vend une promesse séduisante : des robots plus proches d’agents autonomes, capables de s’adapter sans reprogrammation lourde. Mais le chemin entre la simulation académique et l’usine reste jalonné d’écueils.
La question est donc moins de savoir si les robots “penseront” avant d’agir, que de comprendre comment les organisations pourront intégrer ces cerveaux hybrides sans transformer leurs infrastructures en Frankenstein numérique.
